
Regular expression Denial of Service - ReDoS
开发人员使用了正则表达式来对用户输入的数据进行有效性校验, 当编写校验的正则表达式存在缺陷或者不严谨时, 攻击者可以构造特殊的字符串来大量消耗服务器的系统资源,造成服务器的服务中断或停止。
正则匹配的实现
主要有两种方式:确定有限状态机(DFA) & 非确定有限状态机(NFA)
二者都属于有限状态机,但对于DFA, 每一种输入只可能有1个输出状态,对于NFA, 每一种输入可能有多个输出状态
e.g.
graph LR
A("1")--a-->B("2")
A --a--> A
graph LR
A("1")--a-->B("2")
A --b--> C("3")
C --b--> C
C --c--> B
事实上,所有NFA可以转换为等价的DFA,但转换操作的最坏时间复杂度是 其中是节点数。
正则匹配的DFA实现 vs NFA实现
| 实现方式 | DFA | NFA |
|---|---|---|
| 时间复杂度 | 指数级(最坏情况) | |
| 应用范围 | awk(大多数版本)、egrep(大多数版本)、flex、lex、MySQL | Java、grep(大多数版本)、less、more、Perl、PHP(所有三套正则库)、Python、Ruby、set(大多数版本)、vi |
| 功能 | 较少 | 较多,包含分组、替换、分割等特性 |
问题的根源:基于NFA的正则表达式匹配实现存在缺陷
正则表达式的实现算法中,会构造一个非确定有限状态机(NFA), 对于每一个输入,可能会有多个可能的后继状态。NFA不断执行状态转移直到输入结束。由于每一个状态可能有不止一个后继状态,基于NFA的正则表达式匹配需要使用某种算法,遍历状态机中所有可能的路径,直到找到一个匹配的状态(或者找遍所有路径也没有匹配,判断为匹配失败)
例如,正则表达式^(a+)+$ 可以表示为以下NFA:
graph LR
a("1") --a--> b(("2"))
b --a-->d(("4"))
b --a-->c(("3"))
c --a-->c
c --a-->d
d --a-->d
d --a-->e(("5"))
e --a-->e
e --a-->d
图中,1为起始状态,2/3/4/5均为终止状态(若状态转移的终点在2/3/4/5均可视为匹配成功),不难发现,对于每一个终止状态,都存在2条状态转移的路径。这表明输入字符中’a’的数量每增加一位,需要遍历的路径总数会翻倍,匹配的最坏时间复杂度为 $O(2^n) $
例如,匹配aaaaX需要遍历16条路径(才能发现匹配失败),而匹配 aaaaaaaaaaaaaaaaX 则需要遍历65536条路径
在代码实现中,遍历NFA路径的过程经常会用到递归,发现匹配失败时回溯至失败前的上一个状态,但当输入的字符串较为特殊时(例如上面的aa....X) ,会导致递归深度过深,大量占用服务器CPU资源。
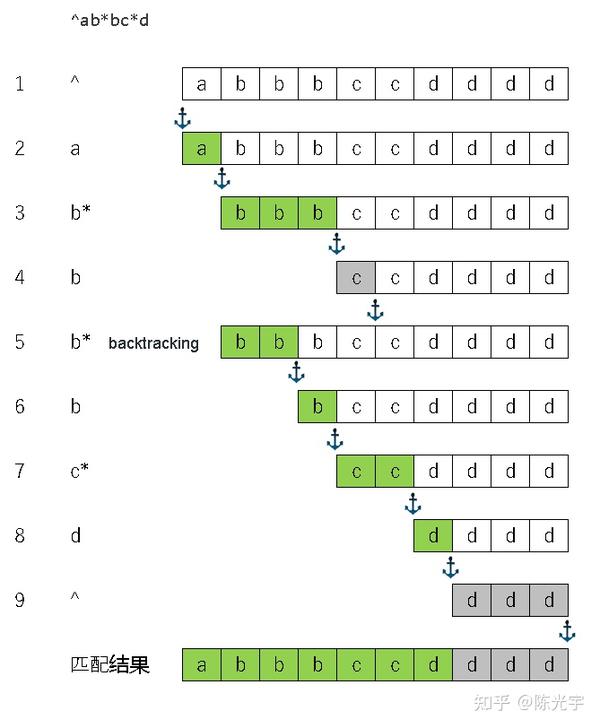
ReDoS攻击
下面是一个示例的python程序
1 | import re |
结果:
1 | Consuming time: 0.0350 |
如果网站的后端/前端逻辑中会运行^(a+)+$这个正则,且它接受未经过滤的用户输入,那么一段含有几十个字母a 的字符串就可以让服务器阻塞。
防范
- 降低正则表达式的复杂度,尽量少用分组
- 限制用户输入的字符串长度,限制匹配时的递归次数
- 人工审查每个正则表达式
- 使用静态代码分析工具/ ReDoS检测工具